Faculty: Kevin Bryan
Research Summary
The Hungarian-American immunologist Katalin Karikó has become a household name over the past year. Her breakthrough discoveries on the therapeutic potential of mRNA led directly to the Pfizer-BioNTech and Moderna Covid-19 vaccines. These vaccines have proven to be the most effective tools we have in suppressing the pandemic.
Any story of Karikó’s work discusses the long arc of her career from a bench scientist working on interferon induction to her research in the 1990s at the University of Pennsylvania on the potential for mRNA-based gene therapy. Consider a policymaker or pharmaceutical CEO who hears this biography. These leaders want to ensure that we do not miss the next Karikó. At an even more basic level, they want to understand exactly what type of “building blocks” allowed Karikó to make her discoveries.
Fundamentally, knowing what allows scientists to succeed requires some ability to measure what resources they use. This is a very challenging problem when the resources in question are ideas from the past. What research motivated Karikó to work on mRNA? What inspired the types of use cases she ended up drawing on? What tools did she use on her research? What breakthroughs by prior researchers allowed her to, as Newton said, “stand on the shoulders of giants” in pushing the knowledge frontier forward?
These are hard questions to answer because ideas are, after all, “in the air”. Scientists do not always write down the antecedents of their own ideas. In some cases, they may not even know what these antecedents are. Consider the famous story from the 19th century German chemist August Kekulé about his discovery of the chemical structure of benzene as the result of a strange dream. Kekulé had been imagining the ancient Egyptian symbol of the ouroboros, a snake eating its own tail. When he awoke, this ouroboros inspired his suggestion that benzene contains a ring structure of single- and double-bonded hydrogen and oxygen. The problem with this story was later discovered by historians of science with access to his lab notebooks: it turns out that the Kekulé was 99% of the way to figuring out his discovery even before the famous dream. Even scientists’ own autobiographies may mislead about what inspired their discoveries!
What we need to trace what inspires scientists and inventors is a contemporary, detailed accounting of those inspirations. As the economists Bronwyn Hall, Adam Jaffe and Manuel Trajtenberg have pointed out, citations in academic papers and patents can play this role, at least in part. It is the norm in academia, and the law when patenting an invention, to cite related research. These citations are now easily available in standardized datasets to researchers. Thousands of studies have looked at questions including how geographically proximate these citations tend to be, whether academic or private-sector research is used more by inventors, how skewed the influence of researchers are, the importance of government-funded research over time, and much more. Biomedical inventions are known to be particularly likely to draw on scientific research.
There is a problem, however. The patent citations commonly used in the literature, known as “front page citations”, are not strictly speaking a measure of influence. Instead, they are a measure of similarity: legally, a patent applicant is obligated to tell the patent office which prior ideas are potentially relevant to the scope of novelty claimed in the invention. One can imagine how conflating similarity with influence can be misleading: a new malaria drug invented using CRISPR to perform basic related research is not similar to CRISPR, but is certainly influenced by it!
We need not throw up our hands, however, alongside my colleagues Yasin Ozcan from the NBER and Bhaven Sampat at Columbia Medical School, with support from the Sandra Rotman Centre for Health Sector Strategy, we have identified an alternative measure to track prior ideas which influence, inspire, or assist inventors. In addition to these legalistic “front page” citations, the text of a patent often includes many references to previous research. For instance, Karikó’s 2005 patent application with Drew Weissman for modified nucleosides in RNA states the following while describing potential uses of their invention:
“In another embodiment, the active compound is delivered in a vesicle, e.g. a liposome (see Langer, Science 249:1527-1533 (1990).”
The Robert Langer article in Science described alternative methods of delivering drugs beyond traditional pills, eyedrops, or injections. This citation refers to a potential application of Karikó and Weissman’s invention.
In another part of the patent, they write:
“Dicer is an RNase III-family nuclease that initiates RNA interference (RNAi) and related phenomena by generation of the small RNAs that determine the specificity of these gene silencing pathways (Bernstein E, Caudy A A et al, Role for a bidentate ribonuclease in the initiation step of RNA interference. Nature 2001; 409(6818): 363-6).”
The Bernstein et al paper gives basic scientific background information on an aspect of RNA interference important to making the invention work.
Further on in the patent:
“The tobacco etch viral 5′ leader and poly(A) tail are functionally synergistic regulators of translation. Gene 165:233) pSVren was generated from p2luc (Grentzmann G, Ingram J A, et al, A dual-luciferase reporter system for studying recoding signals. RNA 1998; 4(4): 479-86) by removal of the firefly luciferase coding sequence with BamHI and NotI digestions, end-filling, and religation.”
The Grentzmann et al paper is, in the context of Karikó and Weissman’s invention, a tool used to create a necessary gene as part of their research. We can see in these examples that the text of the patent contains references to the prior ideas an inventor needs to develop, inspire, or motivate their work.
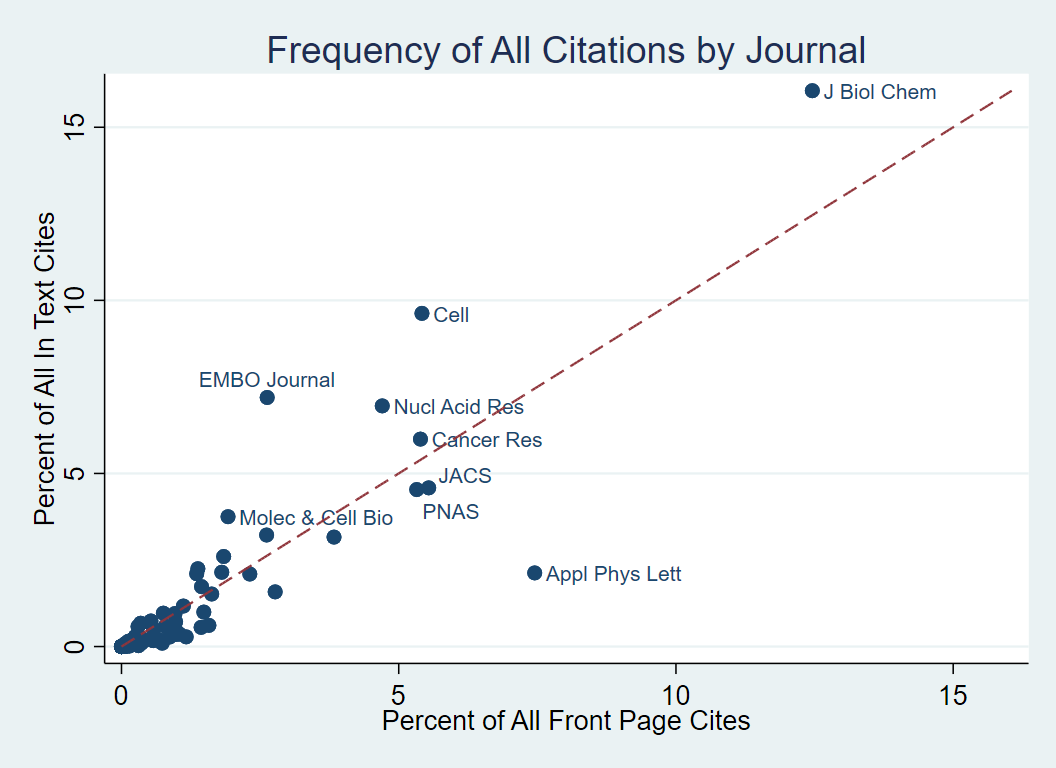
Critically, none of these three research papers are cited on the “front page” of the patent – previous research studying what inventors draw on in their research would have completely missed these influences. And this is not unusual. We use a big data algorithm to scan through the full text of every patent issued in the United States since 1976 to find references to prior science, regardless of the exact format this info is written in. This is not a trivial task, as patents do not have “bibliographies” for references in their text, nor is there any standard format for these citations to appear (Karikó and Weissman give a particularly easy to parse format, but not every inventor is so gracious!). Only 24% of front page citations are given in the patent text, and only 31% of citations in the patent text appear on the front page. Put another way: the vast majority of references prior researchers have used to understand what motivates inventors may be better capturing what is similar between two ideas than what motivates the latter one. As the following figure hints, articles establishing basic scientific facts, or developing novel techniques, were much more likely to be cited in the patent text. We therefore may be undervaluing the importance of basic research and of researcher tools simply because we lacked a good way to measure inventor influences.
We can go further than just looking at front page/in-text differences in citation, thanks to modern machine learning techniques. How? The benefit of citations in the patent text is that there are words around the citation itself. These words help us understand why a prior idea matters for an inventor. We saw that in the three examples above: it was pretty easy for a reader to know that one site was a motivating use-case, one was a piece of background information, and one was a tool used by the researcher. If we had a few thousand paragraphs tagged with the reason why that particular prior idea mattered for the invention, we could use machine learning tools like a Convolutional Neural Net (CNN) to automatically tag millions more citations across patents we had never directly looked at. The idea of these algorithms is that the computer will learn from observing many examples that “use” and “utilize” are synonyms, that a citation following the phrase “we use the process described in…” is likely to be a tool helping make an invention possible, and that combining those ideas “we utilize the process first identified in…” is likely to be one as well.
But how should we initially classify the training set for this algorithm? A natural idea is to ask the inventors themselves. We contacted 10,000 inventors who cited a scientific article in a recent patent of theirs, receiving a reply from 17%. Half of those inventors cited the article on the “front page” and the rest in the patent text. Inventors themselves both classified the relationship between the cited article and the invention, stated how they knew the cited article, and told us how important and similar it was to the invention. In-text citations are 18% less likely to be written by one of the inventors, 8% more likely to have been known by the inventor prior to their invention, and 13% less likely to be related to their invention. This is in line with the idea that in-text citations are more likely to capture inspirations, tools, and motivations for the researcher rather than pure similarity between two discoveries. Tools and techniques are particularly likely to have been missed in earlier studies: citations in the patent text are 42% more likely to be a tool or technique than those cited on the “front page”.
Surveys like this are very expensive: our direct cost per received survey exceeded thirty U.S. dollars, and of course it is impossible at any price to survey an inventor who died in 1998 about their invention in 1977. This is where machine learning is particularly useful. We train the CNN to tag over a million citations using the responses from our inventor survey as ground truth. The algorithm correctly identifies the reason an inventor cites a particular idea over 70% of the time in a holdout sample of survey responses. Although there will be a bit of noise, the benefit to an innovation researcher of being able to draw on approximately 1000 times more data than that on the direct inventor surveys is tremendous. That gives us the statistical power not just to ask “how long does it take for a new research tool to diffuse to other inventors?” but also more complex questions like “is publicly-funded research used by inventors in other countries more quickly if that research is more basic or more applied?”
Ideas may be in the air, but modern computational techniques are giving us the ability to ground them in a precise and measurable way. By combining novel ways to measure influence and the ability of neural nets to “read text” with classic survey evidence, we are able to see much more clearly what types of research are influential and why. These results will both help the public sector better target spending, ensuring we do not miss the next Karikó, and help managers understand what types of useful knowledge their researchers are missing.